人工知能(A.I.)の講義ノート(前編)
「MBA × AI」 の組み合わせで一体どんなことが実現できるだろうか?そんな切り口で最近ではオースラリアでMBAを学びつつ、日本では人工知能(AI)の勉強を開始しています。まずはAIの基礎的な勉強内容を「講義ノート」という形で前編と後編に分けて公開したいと思います。なお、この講義は東京大学情報理工学系研究科博士課程に在籍している山元 浩平氏が講師を務める「AI Dojo」の講義に出席し(2018年3月)そこで得た情報をベースに整理したものです。なお、私はAIの専門家ではないので、恐れ入りますが内容を使用される場合は必ずご自身でも調査や確認をお願いいたします。
<人工知能 A.I.とは>
そもそも「知能」自体の定義もばらばらであり専門家の間でもその定義は様々である。そのため人口知能の明確な定義は存在しないと言える。各研究者の定義の一例を以下に示す。

出典:松尾豊「人工知能は人間を超えるか」KADOKAWA
ただあえて一言で言えば、「その時代において、コンピューターで実現することがギリギリできそうな処理を実現しようとすること。」になるかもしれない。重要なのは、時代の変化に伴いその定義も変化していることである。事実、世界最初のコンピューターENIACが誕生して、わずか10年後にはすでにAIと呼ばれるものがあった。つまり当時はただ「計算できること」がAIと呼ばれていた。つまり、コンピュータが扱う内容が最先端のことでなくコモディティー化すればもはやAIとは言わずに単純に「機能」のような扱いになる。
<人工知能の分類>
一般の人が持つAIのイメージは、おそらく映画「ターミネーター」や漫画「ドラえもん」のように自律しているコンピューターやロボットのようなものと考えているかもしれない。そのようなAIは「強いAI」と呼ばれている。しかし、現時点で「強いAI」は誕生していない。現在開発が進められたり実用化されているのは「弱いAI」である。人間の脳とAI、一般的なソフトウエアの関係を簡単に整理すると以下のようになる。
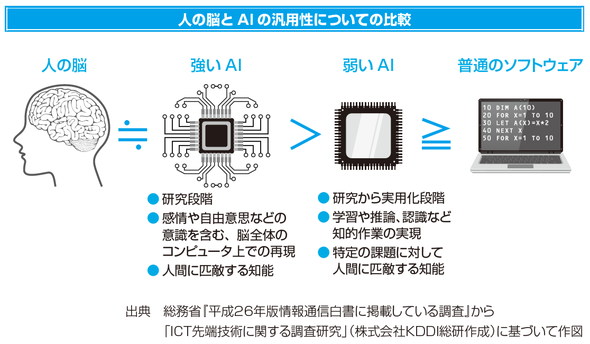
ここで改めて「強いAI」とは、汎用AIであり人間に限りなく近い知能を持ったものと言える。どんな問題にも対応でき自律したものがそれに該当する。一方「弱いAI」は、ソフトウェアの延長線上にあって、問題や課題を設定は基本的には人間が行い、その設定された課題を人間よりも効率的に処理するものである。具体的に、どのようなものがAIとして実現してきたのかは、次の項目で説明する。
<実世界への応用例>
AIが実用化されている代表的な例5つを順に説明する。
①スパム判定システム:受信したメールがスパムかどうか判定して分類や削除する機能。現在ではすでに当たり前の機能として搭載されている場合がほとんどである(あえてAIなどと考えていない人も多い)。
②おすすめ機能(推薦システム):アマゾンの売り上げの1/3以上が推薦によるものとされる。種類としては大きくは「人気順」、「履歴」の二つに分類できる。履歴に関しては、「協調フィルタリング」、「内容ベースフィルタリング」、またはそれぞれのハイブリッド型などがある。協調フィルタリングを簡単に説明すれば、例えばあるユーザーがAとBを買っていたら、Aのみを買ったユーザーにBを推薦するものである。一方、内容ベースフィルタリングは、例えばサッカーの記事を読んだ人なら、サッカー関連の他の商品をオススメするなど内容によっておすすめ商品を決定するものである。なお、おすすめ機能全般について言える問題として、情報が蓄積されていないと新たな提案できない「コールドスタート問題」と呼ばれるものがある。
③指紋認証システム:特定のパターンか否かを判定すれば良いのでコンピューターにとっては比較的簡単である。ただし、顔認証の方が撮る場所や角度、明るさなどが異なるとより変化するためより複雑な処理になる。最近はiPhoneX等で実装されてきた。
④コンピューター将棋、囲碁、チェスなどのゲーム分野:すでに人間よりも優れた成績を収めている。コンピューターでも限られた時間内で打ちうる全通りの計算をするのは困難なため、ある程度選択肢を絞っていく必要があり、そこが人にもコンピューターにも難しいところ。
Alpha GOは、対戦前にものすごい数の前例を読み込ませ事前に学習している。その次に誕生した「Zero」は事前に読み込ませていないのに毎回AlphaGOに勝つことが分かった。これは関係者にとっては非常にショッキングな出来事であった。なぜならば、過去の情報はいらなかったことになるからである。
⑤音声アシスタント:最近各社から次々に同様のサービスや製品が生まれている。例えば、Alexa, Contana, Siri, Google nowなど。
<人工知能の歴史>
AIは最近になって大きく注目されていると思われているかもしれないが、実は今までに(現在のブームも含めて)すでに3回のブームが起き、その後冬の時代に突入してしまった歴史がある。それぞれ第一次から第三次までのブームを順に説明したい。

第一次ブーム:1950-70年頃: 推論と探索「考えるのが早いAI」
世界最初のコンピューターENIACが1946年に誕生してから、わずか10年後にはすでにAIと呼ばれるものがあった。つまり、当時はただ「計算できること」がAIと呼ばれた。探索木(とりあえず行けるところまで行く、幅優先探索)、ハノイの塔などの単純な問題処理ができたが、現実社会の複雑な問題処理には使えず、その後冬の時代を迎える。
第二次ブーム:1980年代: エキスパートシステム、ルールベース「物知りなAI」
すべての出来事やルールを記述することで、より活用できるAIを目指した時代。全ての情報を入れれば人間より賢く対応できるのではないか、という発想に基づき開発された。実際に特定の産業界にはかなり取り入れられた。ただし、最終的には世の中に存在する全ての「ルール」を記述することの限界に直面する。(オントロジー、体系化の限界)なお、ルールというのは、具体的にはIf 文のようなイメージ。例えばゴルフという用語があればスポーツに分類する。同様にインテルならコンピューター。選挙なら政治という具合に分類できる。しかし例えば、ゴルフ+VWなら自動車、インテル+長友ならサッカー、選挙+AKBなら芸能になるかもしれない。このようにルールで物事を指定していくと無限にルールが増えてく。またルールはいずれ膨大になり運用が難しくなる(10万行のプログラムは誰も解明できず、うまく引き継げない問題もある)。さらにルールが変わる場合にはその都度変更が必要になる。
当時、特に顕在化した問題を以下に挙げる。
①フレーム問題:無限の選択肢からどうやって絞るのか、その見極めの難しさ。全く新しい選択肢が生じた場合に対応できない。
②シンボルグランディング問題(記号接地):データからいかに概念とシンボルに帰着させるのかという問題。例えば、シマウマの写真をコンピューターはどう見分けるかを考えてみる。人間であれば「馬」+「しましま」=「シマウマ」のように概念で考えることができる。しかしコンピュータにとっては、ただの白と黒の画像データの集まりに過ぎない。これをシマウマという1つのシンボルに帰着させるのは非常に難しい問題であった。
これらの問題を解決できず、結果として第二次AIブームもその後冬の時代に突入してしまった。
第三次ブーム:2000年:統計的機械学習「データから学ぶAI」
今まではルールを人間が探して書き込んでいたが、この時代ではある大量のデータから自動的にルールを導き出すことが可能になってきた。ただし、データをコンピューターに認識させるには、データから特徴量を抽出する作業が必要になり、あくまでもそれは人間が行なう必要があった。またそれを専門に行う職や人が各分野にいた。なお、特徴量抽出とは、データからどういうデータを取ってくれば、そのデータをうまく分析できるかということである。イメージとしては、年収を予想するときどんなデータが必要か考えてみる。身長、学歴、出生地、年齢などなど取り出すデータが良ければより正確に予測できそうである。この場合の身長や学歴などのデーアの特徴を示すものが特徴量である。ただしこの段階では、データごとにどんな特徴量を抽出すべきかは人が考える必要があった。
第三次の2段 2012年-「ディープラーニング」(機械学習の一種)
それまで人間が設定していた特徴量の獲得までコンピューターが行うことができるようになったため、第三次の2段という分類にできそうである。これによりAIに本当のブレイクスルーが起きたと言われている。そして、これこそが今までのようにAIが一過性のブームではなく、本格的な「AIの時代」が始まったのではないかと多くの人が思うようになった最大の理由である。ここでAI、機械学習、そしてディープラーニングのそれぞれの関係性を下図に示す。人工知能は最初に述べた通りかなり広い概念であり、ディープラーニングは機械学習の一部に分類できる。
![]()
出典:NDIVIA Blog、 https://blogs.nvidia.co.jp/2016/08/09/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/
<なぜ今ディープラーニングがブレイクしているのか?>
ディープラニングが実現してきたのは、AIを取り巻く環境の大きな進展によるところが大きい。代表的な例としては次に示す3つがある。①整備されたデータの増加、②計算機の性能向上(GPU=画像演算=行列の計算が得意)、③機械学習の学問的な発展(例えばデープラーニングに欠かせないューラルネットワークに関する学問的な進展など)
これらの外部環境の変化が今までAIの進展を妨げてきた以下にあげるような問題に対応できる状況を生み出しつつある。①特徴量設計、②フレーム問題、③シンボルグランディング問題。それが今AIがブレイクしている最大の理由である。それが今ディープラーニングがブレイクしている最大の理由である。
ただし現時点では、大量のデータ取得がしやすい画像認識や音声認識の分野に限って発展しているのが現状である。逆にそれ以外の分野ではまだまだ未成熟な状況である。またディープラーニングに対する過度な期待が先行しているのも事実である。AIに関する各研究に関する期待値とその動向を知る有効な方法として、「ガートナーのハイプ・サイクル」(下図)がある。今非常に注目度が高い機械学習(Machine Learning)やディープラーニング(Deep Learning)もゆくゆくは期待値は妥当なレベルまで下がっていくものと考えられる。過度な期待や願望ではなく、実際にどう役立つのかという冷静な視点が必要になりそうである。
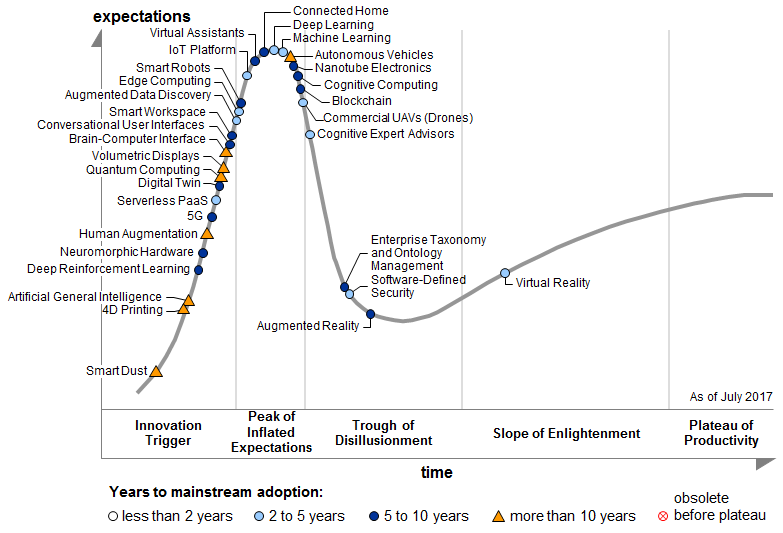
出典:Gartner、Hype Cycle for Emerging Technologies, 2017
<ディープラーニングの今後の発展とAIの未来>
ディープラーニングの今までの経緯や今後の発展の流れを知るにあたり、日本におけるAI研究の第一人者である東京大学「松尾豊」先生の考え方が非常に参考になる。大きくは「認識」「運動」「言語」という流れで進展してきた。公開されている先生のパワポを参考にしながら、各項目について説明していきたい。

出典:松尾豊、人工知能の未来ーディープラーニングの先にあるものー
①認識
1)画像認識:画像から特徴量を抽出することで画像認識の精度が著しく向上した。これはコンピュータにおける「眼の誕生」とも言われている。現在人間と同等の識別レベルまですでに到達した状況である。なお、英語では、人間のReplace(代替)ではなく、Augmented(強化)するという表現が好まれる。
2)マルチモーダル:画像だけではなく、映像(動画)、センサーなどのマルチモーダルなデータから特徴量を抽出しモデル化すること。動画の認識向上、行動予測、異常検知が可能になる段階。
②運動
3)ロボットティクス(行動):これはAiboなどのロボットとは異なる。コンピュータ自身の行動と観測のデータをセットにして特徴量を抽出する作業。シンボル(記号)を操作し行動計画を作る。プラニングや推論ができる段階。
4)インタラクション:外界と試行錯誤することで、外界の特徴量を自ら引き出すこと。これらはオントロジー、高次な状況の認識につながる。
③言語
5)言葉との紐付け(シンボルグラウンディング):高次特徴量を言語と紐づけることで、言語理解や自動翻訳を可能にする段階。
6)言語からの知識獲得:グランウンディングされた言語データの多量入力により、さらなる抽象化を行う。この段階までこれは知識獲得のボトルネックが解決できる。
さらにその先の段階については、松尾豊氏によれば下図のような展開が期待されている。数的操作や対象のモデル化、意識・自己・再帰である。なお、図中の赤色の三角形で示されている領域が、2015年末時点で既に実現されつつある分野である。
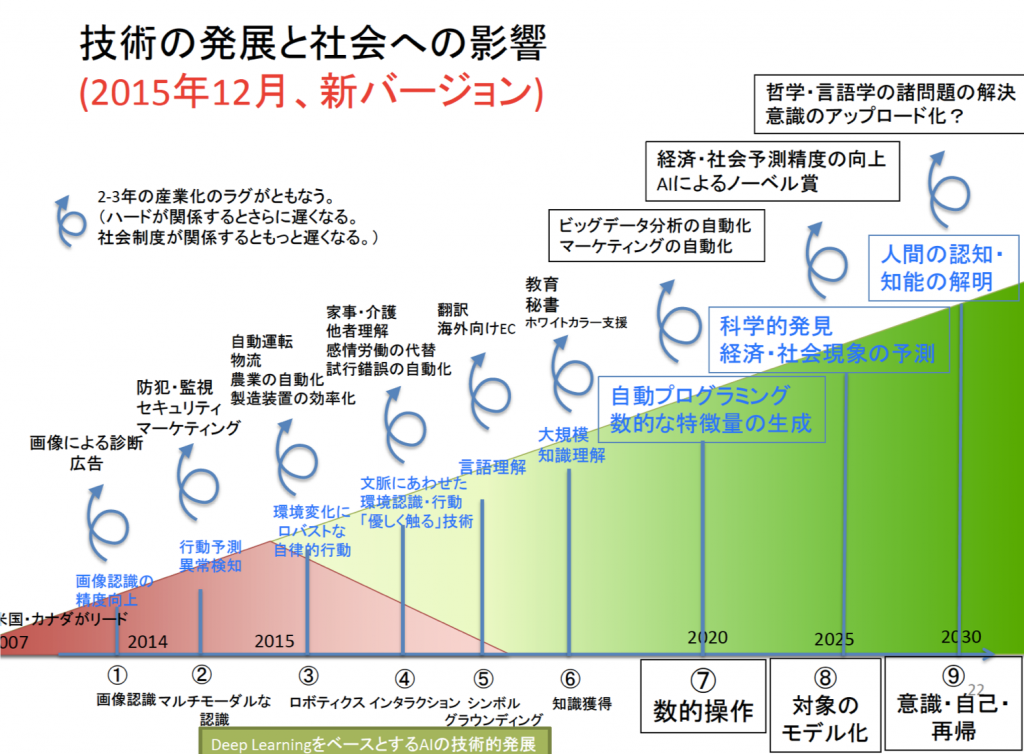
出典:松尾豊、人工知能の未来ーディープラーニングの先にあるものー
さらに将来的には、レイ・カーツワイルが提唱している技術的特異点「シンギュラリティ」の到達が2045年ごろになると予測されている。シンギュラリティとはAIが人間の知能を超える日という意味合いで使われており、「2045年問題」などと言われる場合もある。もしそれが起きれば仕事における人間の役割など社会的にも様々な影響や変化が起こると予想される。ただ変化があまりに早い昨今では、実際には何が起こるのかを予測することは極めて難しいのも事実である。
<機械学習について>
機械学習は特定の産業にのみ有効な技術ではなく、データさえあればどんな産業にでも応用できるという優れた特徴がある。とは言っても、どんな課題や問題にでも「機械学習」が有効というわけでもない。例えば、責任主体、生命の根幹に関わるもの、コミュニケーションなど少なくても現時点ではあくまでも人間がするべきことやした方がよいことも多い。機械学習を適応すべき(強みが活かせる)分野の特徴として、3V(量volume、多様Variety、速度Velocity)がある。大量で、多様で、高速なデータ処理が求められる問題への適応がふさわしいという意味である。特にビジネスでは、「大量」と「高速」なデータ処理が求められる分野がキーになる。例えば、先述の①クレジットカードの不正検知、メールのスパム対策機能、オフィスや製造ラインの異常検知、②大量の商品を扱う推薦システム(おすすめ機能)③Web上でのクリック率×広告料などのリアルタイムな情報に基づく広告配信システム(推薦システム)などでは、どれも「大量」と「高速」なデータ処理が必要になっている。
ここでは機械学習の適応が失敗する典型的なパターンや条件を列挙しておく。
①そもそも機械学習では解決できない不可能な問題設定や精度を求めている場合。例えばサイコロの予測のように完全にランダムな事象であったり、同じ文章内容でも不正の場合も不正でない場合の両者が混在するような問題では適応は不向きである。
②単純すぎるタスク。例えば、人間による処理、ルールベース、分析木で解いた方が早い問題など。
③人がやった方がいいタスク。前述したような責任が生じる問題、生命由来のことやもの、コミュニケーションなどのタスク。
④データ量が少ないもの。整備されたデータ量が少なく、汎用性が確保できないもの。
⑤人的な介在があるもの。例えば、ある分析したいプロセス中に人間の恣意的な判断などが介在している場合など。
前編はここまで。
